Published: April 8, 2021
Summary
- A generative model can be used to collect data to train a deep learning based predictor
In the previous post, we discussed various rule-based predictor-recommender pairs for the PCT framework.
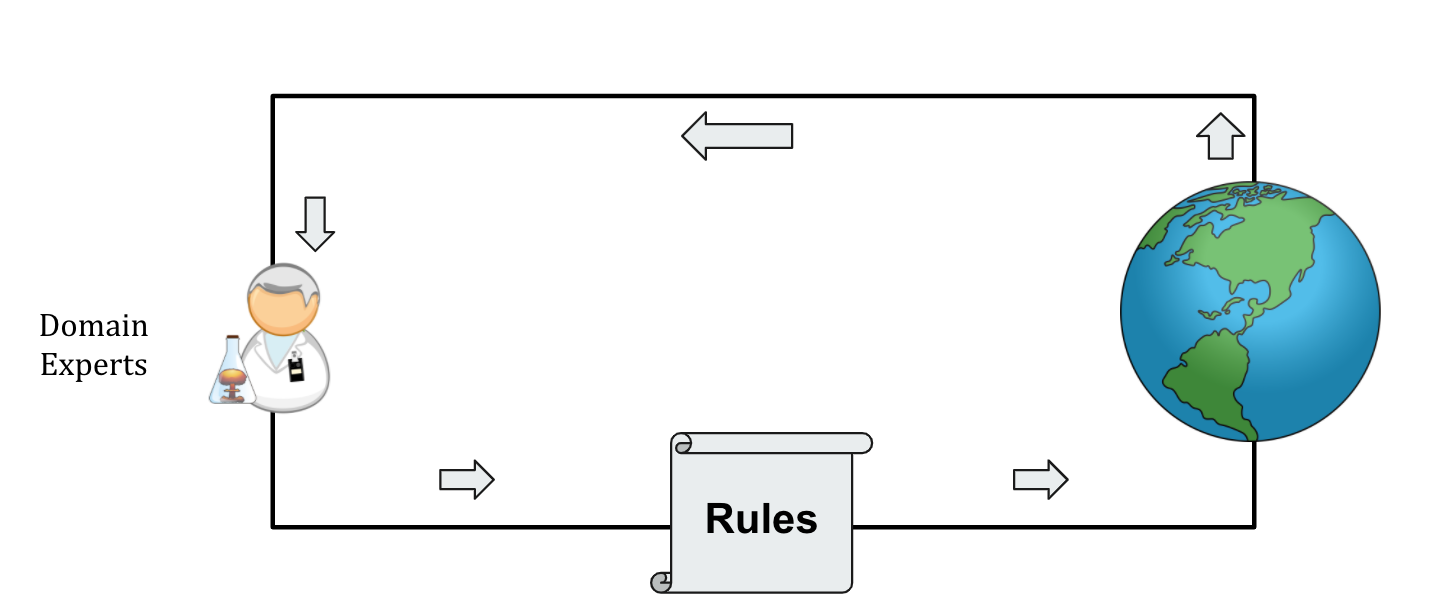
These rules are designed by domain experts, who continually update their understanding of the disease, and accordingly rules, based on the observed data (Figure 4A).
This post explores a machine learning (ML) based methodology that can be useful alongside domain experts.
Figure 4A:
Previously discussed rule-based predictor-recommender pairs are designed by domain experts, who themselves learn from the real world observations.
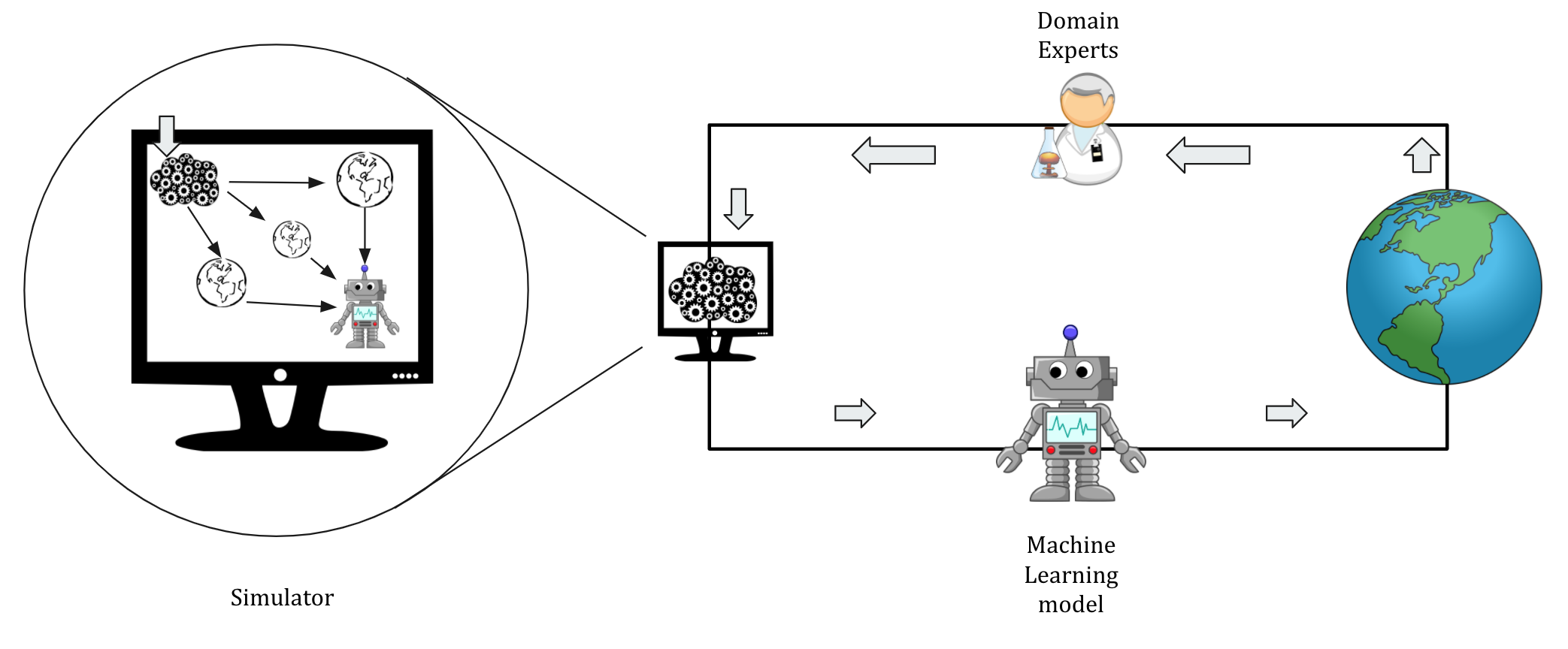
As illustrated in Figure 4B, domain experts use their knowledge to build an approximate generative model (also referred to as a simulator) of an epidemic, and the simulator’s data is, further, used to train the machine learning models.
This simulator is a crude approximation of how the virus spreads through interactions (i.e., who meets whom) in a synthetic population, which is sampled from the census to resemble a particular demographics.
The interactions between synthetic agents (or software individuals) accounts for the mobility patterns and empirically surveyed contact matrices.
Such agent-based models are often used in epidemiology to study the effects of various interventions.
Figure 4B: A generative model built with the help of domain experts can be used to collect data to train the machine learning model. Note that there are several realizations of the simulated world to make the model robust to crude assumptions required to build a generative model.
Deep Learning for PCT
In Bengio et al., an agent-based model, COVI-AgentSim, is used to collect data to train a machine learning predictor-recommender pair for the PCT framework.
For brevity, we will restrict our discussion in this post to the high-level ideas that were crucial to design a deep learning predictor-recommender pair for the PCT framework.
In Bengio et al., we used the simulator to collect observations for each app-user (randomly selected in a population according to age-based smartphone adoption; see section 3.7 of Gupta et al.).
These observations comprise (a) (user-dependent inputs) personal information like pre-existing conditions, daily symptoms, test results, and (b) warning signals received for previous encounters.
The simulator models imperfect user-behavior by using Bernoulli variables for (a).
Through the simulator, we also have access to the underlying ground-truth viral load for each user.
Thus, our objective is to estimate app-users’ viral load for the current day and the past 14 days using personal information (if logged), daily symptoms for the past 14 days (if logged), test results (if logged and verified), and warning signals received in the past 14 days.
A non-zero viral load for the current day will trigger a notification to the app-user recommending cautionary behaviors.
Below are some of the key elements of our trained predictor
- Deep Learning Architecture: - Inputs are treading in the following manner
- daily information about symptoms and test results is aggregated into a single vector for each day (daily health status)
- daily warning signals are aggregated to yield a vector with each dimension representing intensities and the value as the number of such warning signals received
- an offset element denoting a particular day relative to the current day is concatenated to the above vectors
- a vector of personal attributes is used as a separate input
These inputs are then processed by a Deep Set or Set Transformer type architecture to output a vector of 15 scalars (viral load estimate for the current and the past 14 days).
- Domain randomization: Many crude assumptions go into building such a simulator.
Some examples include the dependence of symptoms on the disease phase, grouping of synthetic agents for interactions, or individual viral load curves.
Thus, a single choice of parameters for a simulator is unlikely to reflect reality.
To make the predictor robust to these assumptions, we employ domain randomization over the parameters fueling these assumptions.
The model, therefore, learns from several alternative worlds realized by randomly sampling these parameters.
- Iterative training: Employing this predictor in the simulator (or even the real world) is likely to result in distribution shifts, i.e., eventually, observations will not be representative of those that were used to train the model.
For example, a predictor P0 trained on the dataset D0, when used in the simulator, will, eventually, encounter observations not representative of D0.
To counter this problem, we use iterative training so that a predictor Pn is used in the simulator to collect new dataset Dn+1, which is then used to train a new predictor Pn+1.
We used n = 3 in our experiments.
Simulation Results
Recall from our discussion that we, ideally, want an oracle that accurately predicts an individual’s viral load to control the outbreak with minimum economic disruption.
Thus, the results in Bengio et al. compare this tradeoff between health and economy.
Specifically, BTT (referred by BCT in the paper), a mature heuristic proposed in Gupta et al. (referred by Heuristic), and the above deep learning predictor (referred by DS-PCT or ST-PCT depending on the implementation) are pitted against each other.
Figure 3 in Bengio et al. compares how each of the above methods negotiate the trade-off.
We consider reproductive number of the disease as the proxy for health, and number of contacts allowed as a proxy for the economy.
Each line in the figure is a Gaussian Parametric (GP) regression fit on simulations ran under varying parameters, thereby yielding a model for each method.
The results suggest a better trade-off exhibited by any contact tracing framework, though PCT improves further upon BTT.
Thus, we argue that the PCT framework is essentially a personalization framework that can improve the existing contact tracing methods.
However, some limitations need to be addressed to harness the full potential of this framework.
We discuss these in our next post.
 Prateek Gupta
Prateek Gupta